How to Handle Twitter API 429 Errors: Retry, Backoff & Avoid Them
A developer playbook for Twitter/X API 429 responses: reading x-rate-limit headers, retry-with-backoff patterns, per-endpoint queues, and how to avoid getting throttled at scale. For the full per-endpoint limit reference, see the rate limits page.

The X API (still searched for as the Twitter API) does not give you one rate limit. It gives you a different limit for every endpoint, counted inside one of two rolling windows, and the moment you cross one of them the API stops answering and returns a 429 Too Many Requests. Most developers meet rate limits the hard way: a script that worked at ten requests falls over at four hundred, the error body is terse, and the docs table is rendered behind a login. This guide is the reference that table should have been. It covers the two window types, the per-endpoint numbers as published in 2026, exactly what a 429 looks like on the wire, the retry-with-backoff code that respects the reset timestamp, and the one thing the pay-per-use rollout did not change.
TL;DR: The X API uses two rolling windows: 15 minutes for read endpoints (search, lookup, timelines) and 24 hours for write endpoints (post creation). Each endpoint has its own request budget inside that window, split by auth method: a Bearer (app) token and a user OAuth token draw from separate buckets. When a window is exhausted you get a 429 with an
x-rate-limit-resetheader telling you the Unix timestamp to wait for. The fix is to read that header and back off with jitter, never to hammer the endpoint. Pay-per-use changed billing, not the windows, so the limits still apply. If you are read-heavy and tired of managing windows, a per-call API like GetXAPI has no platform-level window caps at all.
The two window types that govern every X API call
If you only take one idea from this guide, take this: the window is rolling, not fixed. It starts on your first request, not at the top of the clock. That single detail explains most of the "why did I get rate limited early" confusion, and it is where we start.
15-Minute Windows vs 24-Hour Windows: How X API Rate Limits Work
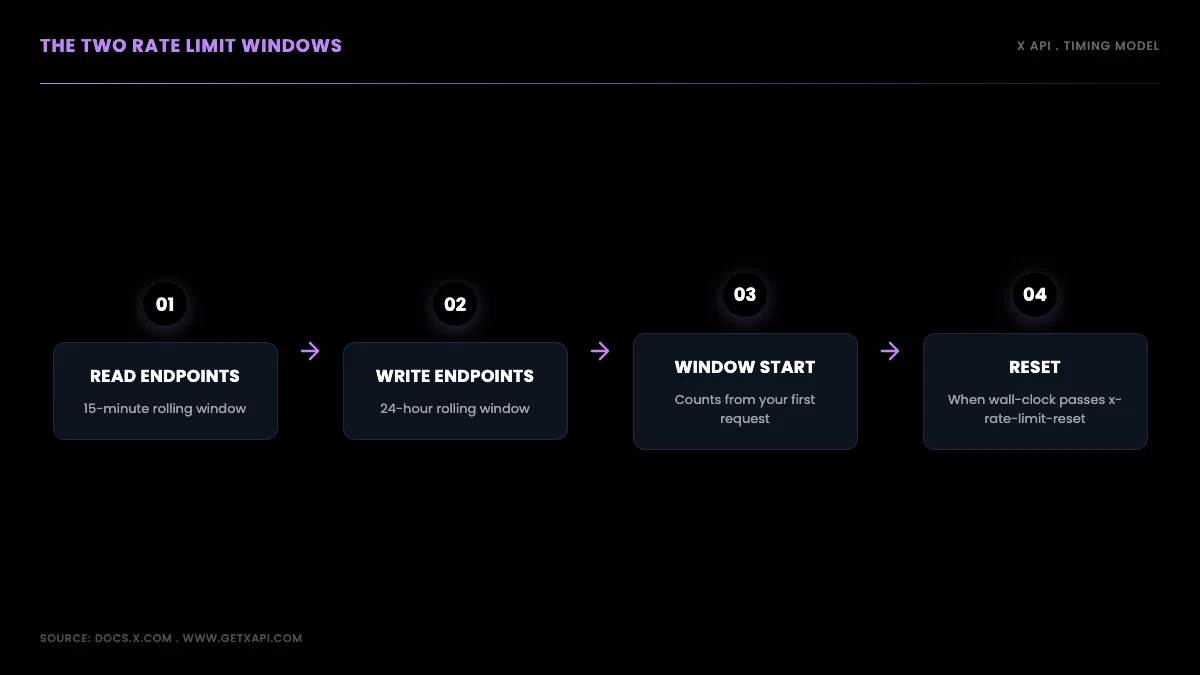
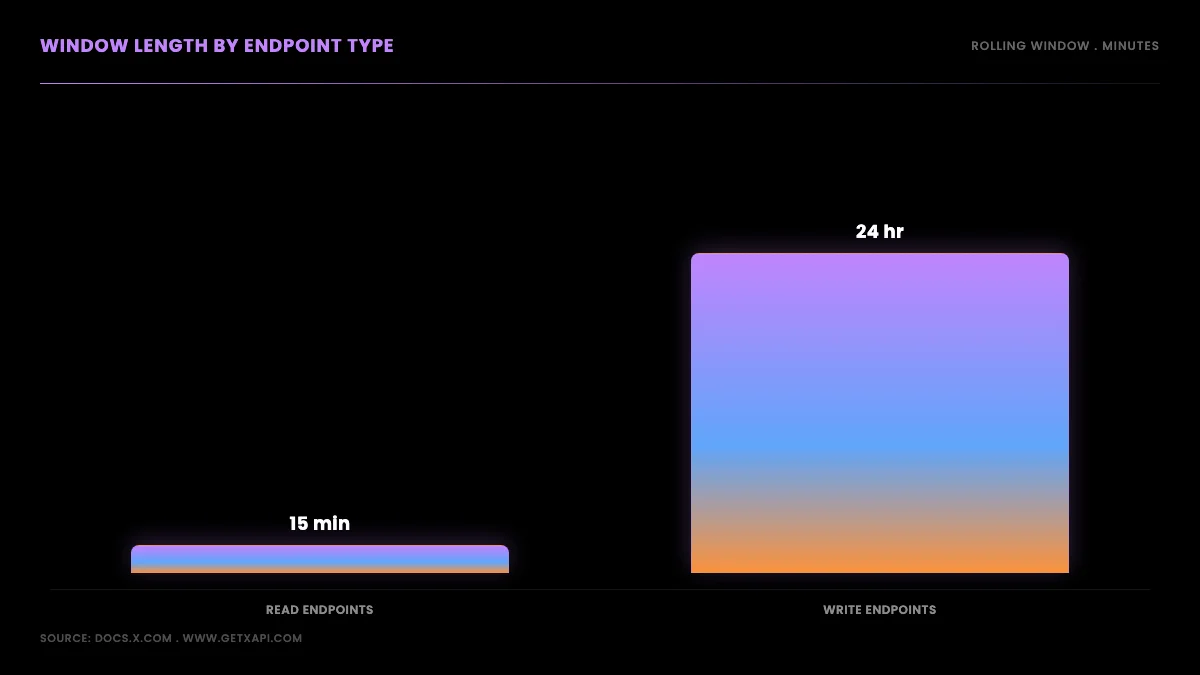
The X API splits its endpoints into two timing regimes. Read endpoints, the calls that fetch data, use a 15-minute rolling window. Write endpoints, the calls that create content, use a 24-hour rolling window. Knowing which regime an endpoint falls into tells you how to budget against it.
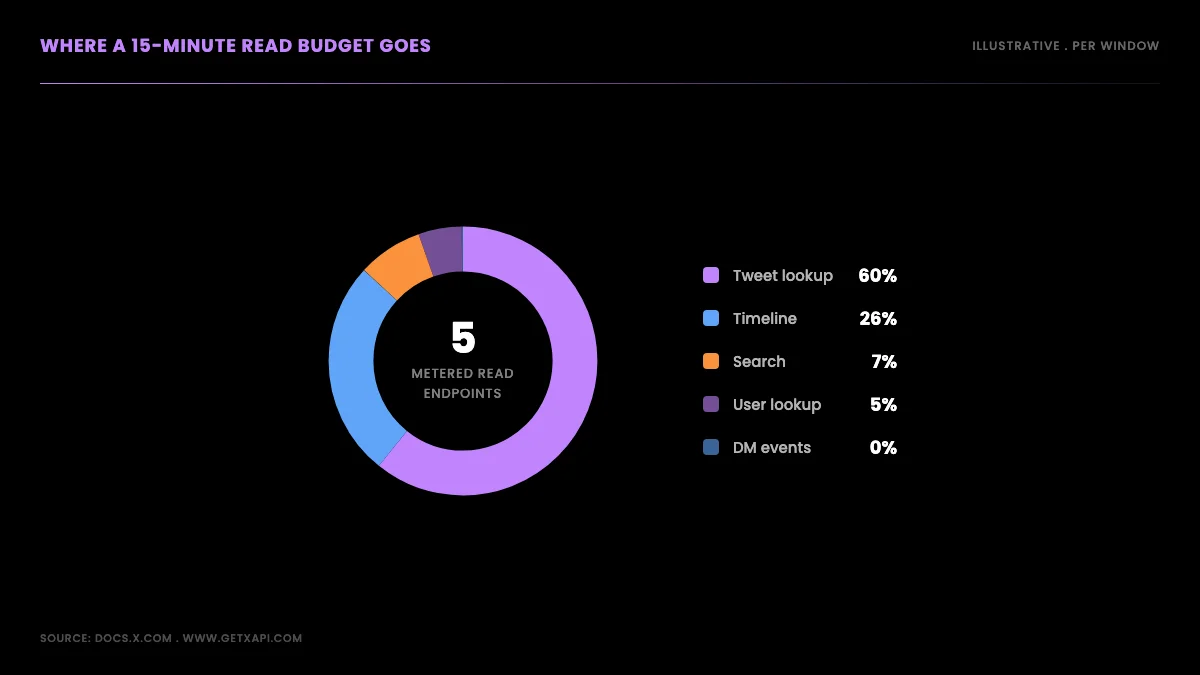
A read is any GET that pulls data out of the platform: searching recent posts, looking up a tweet by ID, reading a user profile, pulling a timeline, fetching DM events. Every one of those is metered in 15-minute blocks. A write is a call that changes state, and in practice that means creating posts through POST /tweets, which is metered across a full 24 hours.
The word rolling matters more than it looks. A rolling window is counted from your first request inside it, not from a fixed clock boundary. If you fire your first search request at 10
, your 15-minute window runs to 10, not to 10. Developers who assume the window snaps to , , , and burn through their budget at the wrong time and get a 429 they did not expect. The window resets when the wall-clock time passes the value in thex-rate-limit-reset header, and not one second sooner.
The free tier is the exception that proves the rule. Because the free tier grants no read access at all, there is no 15-minute read window to think about. The only limit a free-tier developer faces is the monthly post-creation cap, enforced as a running count across the calendar month rather than a per-window budget. We cover the full free tier details and where it leaves you stuck later in this guide.
Here is the mental model for the rolling window, written as a comment rather than code you would run, because the platform does the counting server-side:
# A 15-minute window is rolling, not aligned to the clock.
#
# first_request_at = 10:07:00
# window_resets_at = 10:22:00 (first request + 15 min)
#
# The window resets when wall-clock time passes x-rate-limit-reset,
# NOT when the next :00 / :15 / :30 / :45 arrives.
#
# So always trust the header, never the clock:
# wait_seconds = x_rate_limit_reset - time.time()
That comment is the whole timing concept in nine lines. The rest of this guide is about reading the headers that carry the live numbers, and reacting to them well.
Read versus write window timing at a glance
X API Rate Limits Per Endpoint (2026)
There is no single Twitter API rate limit number, which is exactly why this question is asked so often. Each endpoint carries its own budget, and that budget changes depending on whether you authenticate with a Bearer (app) token or a user OAuth token. The table below collects the current published per-endpoint limits as documented on the X API rate limits reference, cross-checked against the per-endpoint figures GetXAPI tracks for the Twitter API v2 vs GetXAPI comparison.
| Endpoint | Auth method | Window | Limit | Notes |
|---|---|---|---|---|
| GET /tweets/search/recent | Bearer (app) | 15 min | 450 req | Most common search endpoint |
| GET /tweets/search/recent | OAuth (user) | 15 min | 300 req | Per-user bucket |
| GET /tweets/ (lookup) | Bearer (app) | 15 min | 3,500 req | Batch up to 100 IDs per call |
| GET /tweets/ (lookup) | OAuth (user) | 15 min | 5,000 req | Higher in user context |
| GET /users/ | Bearer (app) | 15 min | 300 req | User profile lookup |
| GET /users/ | OAuth (user) | 15 min | 900 req | Per-user bucket |
| GET /users//tweets | Bearer (app) | 15 min | 1,500 req | User timeline |
| GET /dm_events | OAuth (user) | 15 min | 15 req | DM events, strict limit |
| POST /tweets | Bearer (app) | 24 hr | 10,000 req | Write endpoint |
| POST /tweets | Free tier | Monthly | 1,500 posts | Monthly cap, not per-window |
The numbers above reflect the standard published limits as of mid-2026. X adjusts per-endpoint ceilings with the tier model and occasional policy changes, so treat the table as a planning baseline and read the live x-rate-limit-limit header for the authoritative value on any given call. Where a specific figure cannot be confirmed against the live docs for your tier, assume the lower number and budget conservatively.

Per-endpoint request budgets by auth method
Two patterns are worth lifting out of the grid. First, lookup is far more generous than search: a Bearer token gets 3,500 lookup calls per window against only 450 searches, and because lookup batches up to 100 IDs per call, that is hundreds of thousands of tweet objects per 15 minutes if you have the IDs. Second, the DM events endpoint is brutally tight at 15 requests per window, which catches teams building inbox tools off guard; the Twitter DM API rate limits guide covers that endpoint family in depth. If your read pattern lets you resolve IDs first and lookup in batches, you sidestep the search ceiling entirely. The advanced search operators guide covers how to narrow a search so you pull fewer, denser pages, and the broader Twitter API tutorial walks the full v2 endpoint surface end to end.
The most important callout on this whole table is what does not appear: there is no row where pay-per-use billing raises or removes these caps. The per-call billing model changed your invoice, not your request budget. A search endpoint is still 450 per 15 minutes on a Bearer token whether you pay a subscription or pay per resource. We come back to that in the pay-per-use section because it is the single most common 2026 misconception.
Rate Limiting Explained: ever tried to hit an API too many times and got blocked with "429 Too Many Requests"?
— @shreyassihasane view on X
What a 429 Too Many Requests Response Looks Like
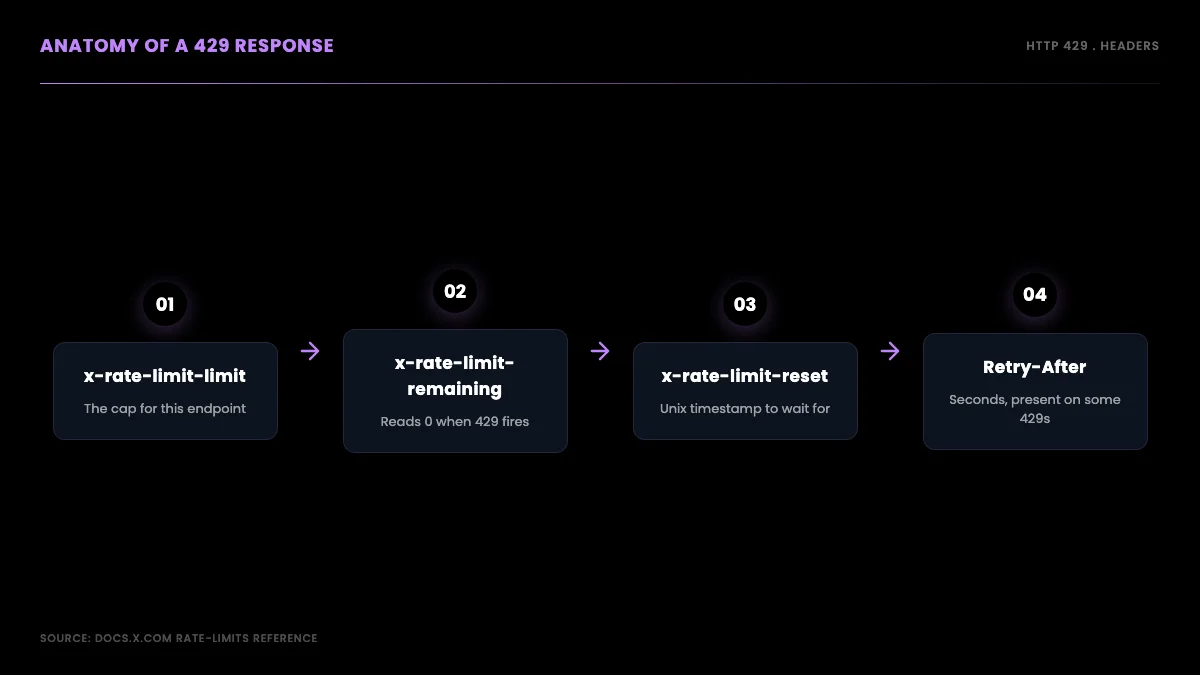
When you exhaust an endpoint's budget, the API returns HTTP status 429 Too Many Requests. The body is terse, so the useful information lives in the response headers, and learning to read them turns a mysterious failure into a precise wait time.
Three headers govern every metered call. x-rate-limit-limit is the cap for the endpoint in the current window, which is the same number you saw in the table above but read live from the server. x-rate-limit-remaining counts down toward zero with each request and reads 0 on the response that triggers the 429. x-rate-limit-reset is a Unix epoch timestamp marking the exact second the window resets, and it is the single most useful value on the entire response. Some 429 responses also include a Retry-After header expressed in seconds, but it is not present on every endpoint, so your code should prefer the reset timestamp and treat Retry-After as a fallback. The full set of header names is documented on the X API rate limits reference and matches the standard 429 Too Many Requests definition in the HTTP spec.
A 429 is not the only error you can get, and confusing it with its neighbors wastes time. A 403 Forbidden means your tier has no access to the resource, so retrying will never succeed; it is a tier problem, not a timing problem. A 401 means your credentials are wrong. A 503 means the server is overloaded, which you should retry with backoff but which has nothing to do with your rate budget. Only the 429 is a true rate-limit signal, and only the 429 is fixed by waiting for the reset.
The headers that turn a 429 into a precise wait time
Here is the smallest useful piece of code: a function that turns a 429 response into the number of seconds to wait, preferring the reset timestamp and falling back to Retry-After.
import time
import requests
def get_wait_seconds(response):
if "x-rate-limit-reset" in response.headers:
reset_ts = int(response.headers["x-rate-limit-reset"])
return max(reset_ts - time.time(), 1)
if "Retry-After" in response.headers:
return float(response.headers["Retry-After"])
return 60 # safe fallback when no header is present
resp = requests.get(ENDPOINT, headers=AUTH_HEADERS)
if resp.status_code == 429:
wait = get_wait_seconds(resp)
print(f"Rate limited. Waiting {wait:.0f}s until reset.")
time.sleep(wait)
That max(..., 1) guard matters: clock skew between your machine and X's servers can make the reset look like it already passed, and you never want to sleep a negative number. Floor the wait at one second and move on.

429 is recoverable by waiting; 403 and 401 are not
Twitter API 429 vs 403 vs 503: Which Errors to Retry
The retry code in the next section hinges on one decision your client makes on every failed response: should I wait and try again, or is this request structurally doomed? Get that decision wrong and you either burn your retry budget on requests that will never succeed, or you give up on requests that would have worked after a short wait. Four status codes cover almost everything the X API throws at a read loop, and they split cleanly into retry and do-not-retry.
A 429 is the only true rate-limit signal, and it is always worth retrying after the wait computed from x-rate-limit-reset. A 503 Service Unavailable means the server is briefly overloaded and has nothing to do with your budget, so retry it with plain exponential backoff and no reference to the rate-limit headers. Those two are recoverable. On the other side, a 403 Forbidden means your tier has no access to the resource, which retrying will never fix, and a 401 Unauthorized means your credentials are wrong, which retrying will also never fix. A 400 Bad Request means your query is malformed. None of the 4xx errors except 429 should ever be retried, because waiting changes nothing about a request that is wrong on arrival.
The trap that catches developers is treating a 403 like a 429. The two look superficially similar (both are the API saying no) but they mean opposite things: a 429 says "not right now" and a 403 says "not ever, on this tier." A loop that retries a 403 will spin through its entire retry budget, add load, and still fail, while a loop that retries a 429 recovers cleanly. The next section encodes exactly this split into the retry decorator: 429 and 503 get backoff, everything else raises immediately.
Start building with GetXAPI
$0.05 per 1,000 tweets. $0.10 free credits. No credit card required.
How to Retry a 429: Exponential Backoff With Jitter
Knowing how long to wait is half the job. The other half is retrying without making the problem worse, which is where exponential backoff and jitter come in. Backoff means each retry waits longer than the last; jitter means each retry waits a slightly random amount so that many workers do not all retry at the same instant.
The reason jitter is not optional is the thundering-herd problem. Picture a hundred worker processes that all share a Bearer token and all hit the search ceiling at the same moment. Without jitter, all hundred read the same reset timestamp, all sleep the same duration, and all retry in the same millisecond, which exhausts the freshly reset window instantly and triggers a fresh round of 429s. A small random offset spreads those retries across a few seconds and lets the window drain in order. This is standard distributed-systems hygiene, and it is the difference between a backoff loop that recovers and one that oscillates.
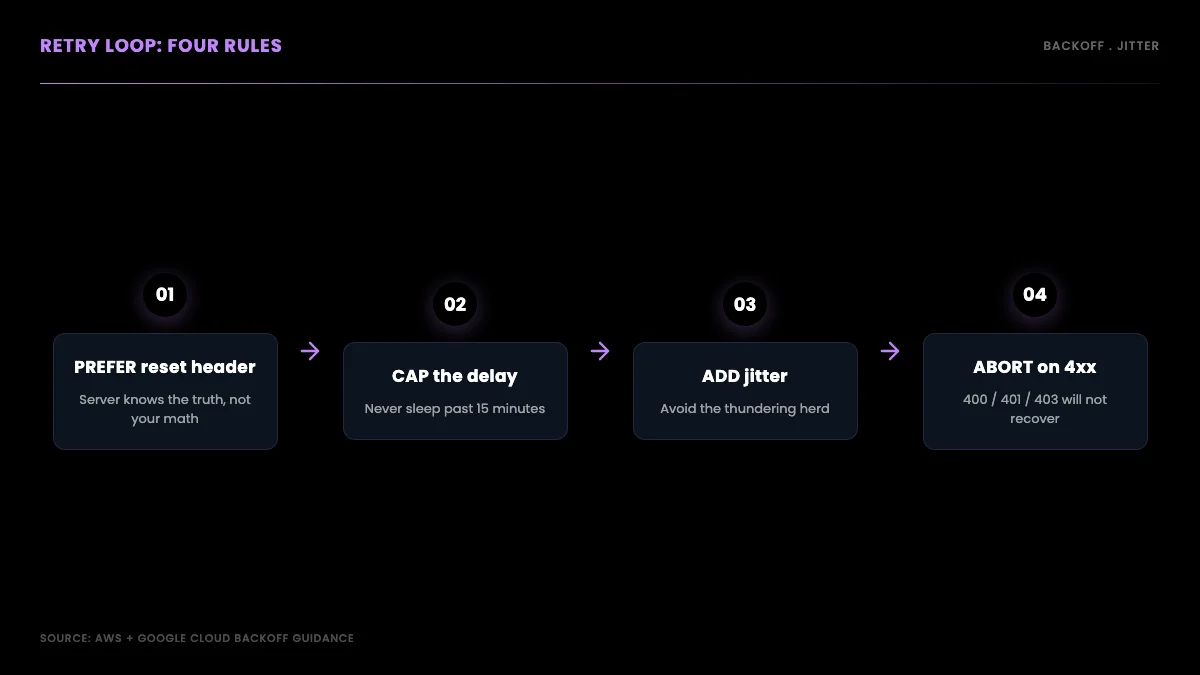
The pattern has four rules. Prefer x-rate-limit-reset over any computed delay, because the server knows the truth and your math is a guess. Cap the computed delay so a high attempt count cannot sleep for an absurd duration. Add jitter proportional to the wait. And hard-abort on permanent errors: a 400, 401, or 403 will never succeed on retry, so raise immediately rather than burning your retry budget on a request that is structurally broken.
Here is the full retry decorator in Python, the version you would actually drop into a production read loop:
import time
import random
import requests
def request_with_retry(url, headers, max_retries=5, base_delay=5):
for attempt in range(max_retries):
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
return resp
if resp.status_code == 429:
if "x-rate-limit-reset" in resp.headers:
wait = max(int(resp.headers["x-rate-limit-reset"]) - time.time(), 1)
else:
wait = min(base_delay * (2 ** attempt), 900)
jitter = random.uniform(0, wait * 0.1)
print(f"429 on attempt {attempt + 1}. Waiting {wait + jitter:.1f}s.")
time.sleep(wait + jitter)
elif resp.status_code in (502, 503):
wait = min(base_delay * (2 ** attempt), 60) + random.uniform(0, 2)
time.sleep(wait)
else:
resp.raise_for_status() # 400, 401, 403: do not retry
raise RuntimeError(f"Max retries exceeded for {url}")
The same logic in Node.js, for a JavaScript stack, follows the identical four rules:
const axios = require("axios");
async function requestWithRetry(url, headers, maxRetries = 5, baseDelay = 5000) {
for (let attempt = 0; attempt < maxRetries; attempt++) {
try {
const resp = await axios.get(url, { headers });
return resp.data;
} catch (err) {
const status = err.response?.status;
if (status === 429) {
const reset = err.response.headers["x-rate-limit-reset"];
const waitMs = reset
? Math.max(parseInt(reset) * 1000 - Date.now(), 1000)
: Math.min(baseDelay * Math.pow(2, attempt), 900000);
const jitter = Math.random() * waitMs * 0.1;
await new Promise((r) => setTimeout(r, waitMs + jitter));
} else if ([502, 503].includes(status)) {
await new Promise((r) => setTimeout(r, baseDelay * Math.pow(2, attempt)));
} else {
throw err;
}
}
}
throw new Error(`Max retries exceeded for ${url}`);
}
The four rules of a well-behaved retry loop
Both versions convert the reset timestamp to a wait, cap the fallback delay at 15 minutes (the maximum a read window can possibly be), add proportional jitter, and refuse to retry structural errors. The community Tweepy library wraps a version of this for you if you build against the official API in Python, and the production scraping best practices guide shows how to wire the same pattern into a long-running pipeline. For the request syntax that feeds these loops, the Python Twitter API tutorial is the companion walkthrough.
the r/learnpython thread on getting error 429 too many requests from the Twitter API from r/learnpython
Reading x-rate-limit-remaining Before You Hit Zero
Retrying after a 429 is reactive. The better pattern is proactive: read x-rate-limit-remaining on every response, not just on failures, and slow down before you hit zero. A 429 costs you a full window of dead time; a proactive throttle costs you a few milliseconds of sleep spread across many requests and never triggers the error at all.
The idea is simple. Every successful response carries the remaining count and the reset timestamp. If the remaining count drops below a threshold you choose, spread your remaining requests evenly across the time left in the window instead of firing them as fast as the network allows. You trade a little throughput now for never paying the full window penalty later.
Here is a throttle wrapper that does exactly that. It checks the remaining budget on each response and, when it dips below a floor, sleeps long enough to pace the rest of the window:
import time
import requests
def safe_request(url, headers, min_remaining=50, slow_down_factor=2):
resp = requests.get(url, headers=headers)
remaining = int(resp.headers.get("x-rate-limit-remaining", 9999))
reset_ts = int(resp.headers.get("x-rate-limit-reset", time.time() + 900))
if remaining < min_remaining and resp.status_code == 200:
window_seconds_left = max(reset_ts - time.time(), 1)
sleep_per_request = window_seconds_left / max(remaining, 1)
time.sleep(sleep_per_request * slow_down_factor)
return resp
The defaults are conservative on purpose. A floor of 50 remaining requests gives you margin to absorb a burst, and a slow-down factor of 2 doubles the spacing so you are unlikely to graze the limit even under jitter. Tune the floor up for high-concurrency workloads where several workers share a bucket, and down for single-threaded scripts where you have the whole budget to yourself. For real-time monitoring jobs that must keep reading, pair this throttle with a request queue so that work backs up gracefully instead of failing. The Twitter trends API guide covers a polling pattern that benefits directly from this kind of pacing.
The backoff-with-jitter pattern from the previous section is not a Twitter-specific invention. It is the standard cloud guidance for any rate-limited API, documented in the AWS architecture guidance on exponential backoff and jitter and the Google Cloud retry strategy reference. Following the same pattern X expects keeps your client well-behaved across every API you call, not just this one.
How to Check Your Current Rate Limit Status
Before you write a single read call, it helps to know which tier and which limit regime your credentials sit in. The fastest way is a HEAD request that returns the rate-limit headers without consuming a full response body, which lets you inspect your budget cheaply.
# Inspect rate-limit headers on a read endpoint without parsing a full body
curl -sI "https://api.x.com/2/tweets/search/recent?query=test&max_results=10" \
-H "Authorization: Bearer $X_BEARER_TOKEN" \
| grep -i "x-rate-limit\|x-access-level"
The response carries the three headers covered earlier plus an x-access-level value that tells you whether you are on the write-only free tier, on pay-per-use, or on a legacy subscription. If reads return 403 and the access level reads write-only, you are on the free tier and the per-window read limits are moot because you have no read access to meter. If reads succeed, the x-rate-limit-limit header is your authoritative per-window budget, more reliable than any published table because it reflects your exact account state. The header semantics follow the standard HTTP rate-limit header conventions, and the underlying retry behavior is governed by the 429 status definition in RFC 6585. Reading your live status first stops you from planning against a number that does not apply to your tier, which is the cheapest mistake to avoid in this entire space.
App-Level vs User-Level Rate Limits: Bearer Token vs OAuth 1.0a
One of the deepest sources of rate-limit confusion is that the same endpoint has two different limits depending on how you authenticate. A Bearer token and a user OAuth token draw from completely separate buckets, and understanding the distinction can multiply your effective throughput.
A Bearer token is app-level authentication. There is one bucket per app token, and every call made with that token counts against the same shared budget. If your service uses a single Bearer token to serve a thousand users, all thousand users share one 450-request search window. A user OAuth token is per-user authentication. Each authenticated user's token has its own independent bucket and its own independent window. The same thousand users, each authenticated with their own OAuth token, each get their own 300-request search window.
The practical consequence is large. The numbers per call are lower on OAuth (300 search requests versus 450 on Bearer), but the buckets are independent, so total capacity scales with your user count instead of being capped by a single app bucket. For a high-volume multi-user app, OAuth user tokens are the way to multiply effective throughput; for a single-tenant backend job, the Bearer token's higher per-bucket ceiling is simpler and enough. The same bucket logic governs endpoint-specific reads like follower lists, covered in the export Twitter followers guide, and the long-form read endpoints in the Twitter Article API tutorial.
| Auth type | Search limit per 15 min | Bucket scope |
|---|---|---|
| Bearer token (app) | 450 req | Shared across every call using this app token |
| OAuth 1.0a (user) | 300 req | Per authenticated user token, independent windows |

Why OAuth multiplies throughput for multi-user apps
This is also the answer to the most common Reddit question in this space: "why does my search 429 after 300 requests when the docs say 450?" The answer is almost always that the code is using user OAuth (the 300 bucket) while reading the Bearer-token number from the docs (the 450 bucket). Match the limit you plan against to the auth method you actually use. The auth flows themselves are covered in the how to get a Twitter API key walkthrough and on the Twitter API key page, and the bucket distinction shows up again in the Twitter API v2 vs GetXAPI comparison.
Getting "rate limit exceeded" on X API. Does anyone know what's the issue?
— @devfaizanali view on X
The cheapest Twitter API. Try it free.
$0.05 per 1,000 tweets. $0.10 free credits. No credit card required.
Does the Pay-Per-Use Model Remove Rate Limits?
No. This is the single most common misconception about the 2026 X API, and it costs developers real money when they build on the assumption that paying per call buys unlimited speed. Pay-per-use changed how you are billed, not how fast you can send requests.
Under the pay-per-use model you prepay credits and each call deducts its per-operation price. That is a billing change. The 15-minute and 24-hour rate-limit windows still apply on top of it, exactly as they did under the legacy subscription tiers. A search endpoint is still 450 requests per 15 minutes on a Bearer token whether you are on pay-per-use or grandfathered into an old plan. You will still get a 429 when a window is exhausted, and you will still need the retry-with-backoff code from earlier in this guide.
What pay-per-use does add is a second, separate kind of limit: a calendar-month read ceiling. Where a 429 is a timing limit you recover from by waiting minutes, the monthly cap is a hard ceiling you do not recover from until the next billing period. The two limits fail differently. Hit a window cap and you get a 429 with a reset timestamp. Approach the monthly cap and your account is pushed toward Enterprise pricing instead. This means a pay-per-use integration has to handle both: backoff for the per-window 429s, and spend monitoring for the monthly ceiling. The pay-per-use pricing model page and the Twitter API cost breakdown lay out where each limit bites, and the cost calculator models the spend curve before you write a line of code.
What pay-per-use changed, and what it did not
The takeaway is blunt: pay-per-use is not a rate-limit escape hatch. If anything it adds a limit. The only way to genuinely remove the per-window problem is to leave the official API's window model entirely, which is the last section of this guide.
Rate Limits Across X API Tiers in 2026
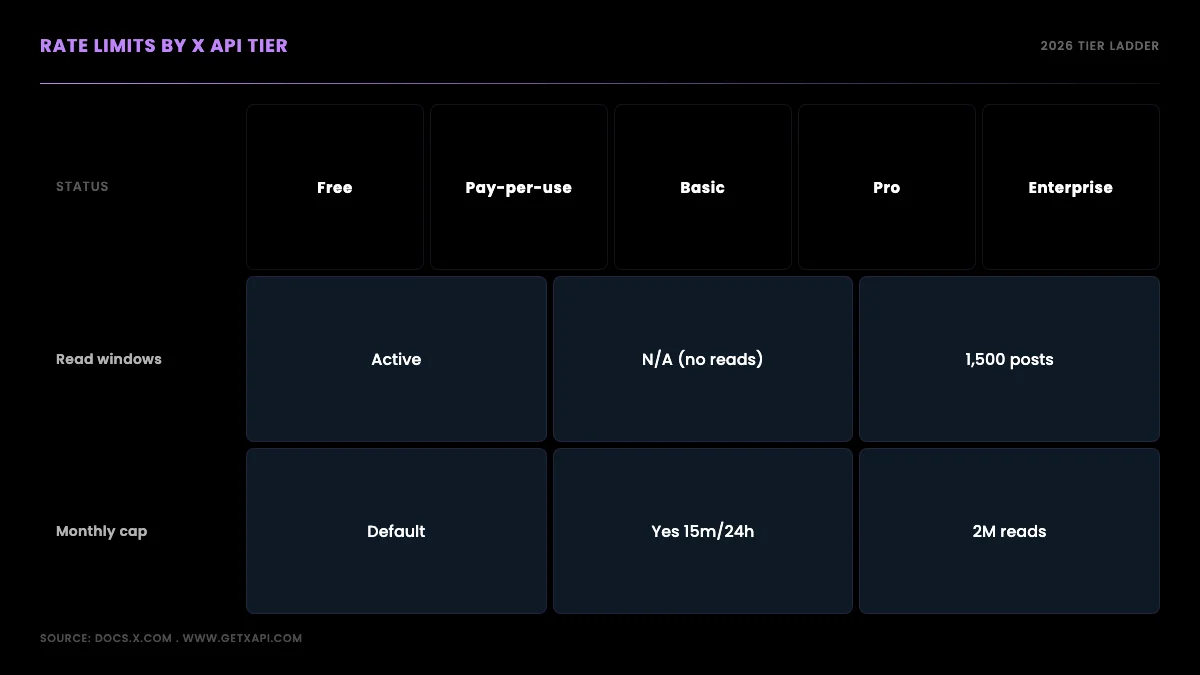
Rate limits do not exist in a vacuum; they sit inside the tier model, and the tier model changed sharply in 2026. Knowing which tier you are on tells you which limits apply and which simply do not.
| Tier | Status | Per-endpoint windows apply | Monthly billing cap | Write limit |
|---|---|---|---|---|
| Free | Active | N/A (read endpoints blocked) | 1,500 posts / month | Post-only |
| Pay-per-use | Active (new default) | Yes, standard 15-min / 24-hr windows | 2M post reads / calendar month | Per-call billed |
| Basic | Closed to new signups (Feb 2026) | Yes (legacy) | 15K reads / month | 50K posts / month |
| Pro | Closed to new signups (Feb 2026) | Yes (legacy) | 1M reads / month | 300K posts / month |
| Enterprise | Active | Negotiated limits | Custom | Custom |
Where rate limits apply across the 2026 tier ladder
Walk it tier by tier. The free tier has no per-endpoint read windows to worry about because it has no read access at all; its only limit is the 1,500-post monthly write cap. Pay-per-use, now the default for new developers, faces the full standard window model plus the 2-million-read calendar-month ceiling described above. The Basic and Pro subscription tiers, which bundled fixed quotas, closed to new signups in February 2026, so a new developer cannot buy them; existing subscribers were migrated onto pay-per-use. Enterprise remains active with negotiated limits and is the forced destination above the pay-per-use read ceiling. The legacy tier closure is tracked in detail on the Twitter API pricing page and in the Twitter API cost breakdown; verify the current month-cap numbers against docs.x.com for your specific account, since X has adjusted these during the transition.
The practical lesson for planning: if you signed up in 2026, you are almost certainly on pay-per-use, which means you face both the per-window 429s and the monthly read ceiling. If you are reading legacy tutorials that describe Basic or Pro quotas, those numbers no longer apply to a new account. Budget against the pay-per-use reality. To compare the official tiers against third-party read providers head to head, the Twitter API alternatives comparison and the best Twitter API for scraping breakdown lay out the options, and the Apify Twitter scraper vs GetXAPI and RapidAPI Twitter alternative posts cover how marketplace providers price the same reads.
the r/datasets thread on pulling Twitter/X data at scale without getting rate limited from r/datasets
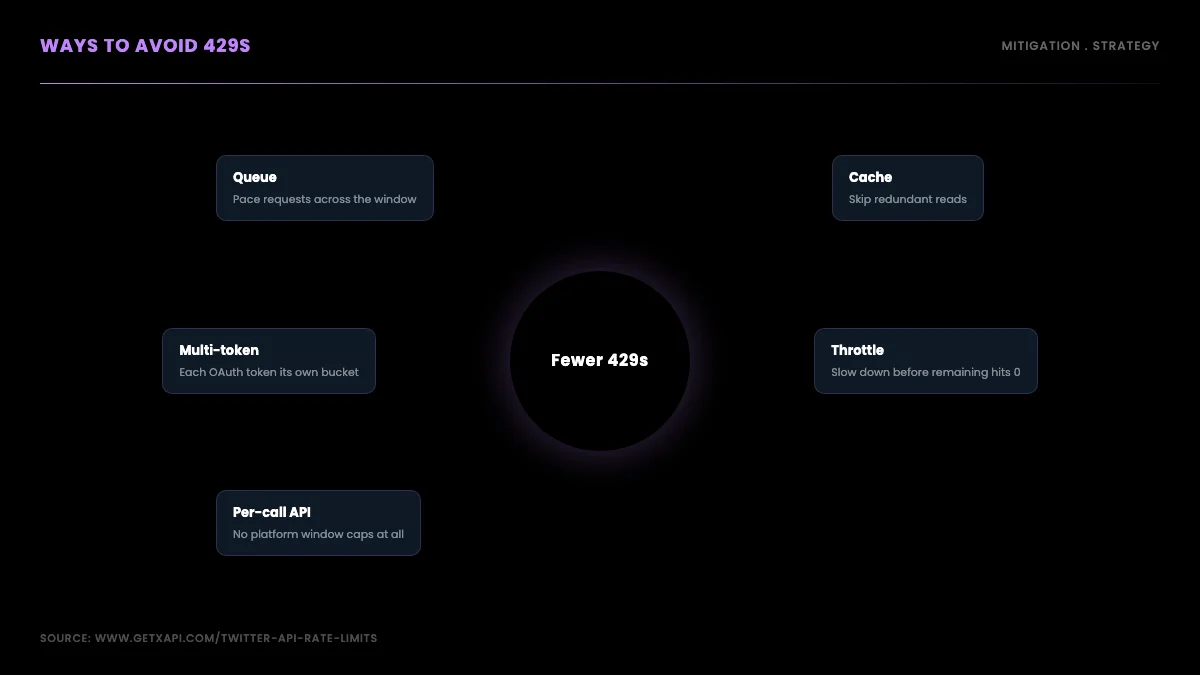
How to Avoid 429s Entirely: Per-Call APIs With No Window Caps
Everything above is how you live inside the official window model gracefully. There is one way to step outside it: a third-party read API that bills per call and enforces no platform-level rate-limit windows. For read-heavy work, this removes the 429 problem rather than managing it.
GetXAPI is built this way. It charges per call and does not impose 15-minute or 24-hour window caps, so there is no x-rate-limit-remaining to track and no window exhaustion to back off from. The only ceiling is your credit balance. That changes the shape of your code: the elaborate retry-and-throttle scaffolding from the earlier sections shrinks to a simple request plus a guard for transient network errors. You are no longer fighting the platform's timing gates, because there are none.
Ways to soften or sidestep the window problem
This matters most for three workload shapes. Read-heavy pipelines, like sentiment analysis over thousands of tweets, where the official 450-per-window search ceiling forces constant pacing. Real-time monitoring, where request cadence is bursty and unpredictable and a 429 mid-burst loses data. And research tasks, where you pull a large dataset once and the window math turns a five-minute job into an hour of sleeping. The trade-off is the billing model: per-call pricing versus a subscription, which the pricing page and the cost calculator let you compare against your expected volume.
Here is the same recent-search read that costs you window management on the official API, made against a per-call API with no rate-limit scaffolding required. This request was executed live against the GetXAPI search endpoint before publishing:
import os
import requests
API_KEY = os.environ["GETXAPI_KEY"]
resp = requests.get(
"https://api.getxapi.com/twitter/tweet/advanced_search",
params={"q": "twitter api rate limit", "queryType": "Latest"},
headers={"Authorization": f"Bearer {API_KEY}"},
)
resp.raise_for_status()
payload = resp.json()
print("matched tweets:", payload["tweet_count"])
for t in payload["tweets"][:5]:
print(t["createdAt"], "@" + t["author"]["userName"], t["text"][:70])
# No x-rate-limit headers to parse; no backoff loop for normal-volume reads.
There are no rate-limit headers on that response to inspect and no window to wait on. You would still wrap a long-running job in a small retry for transient 5xx network errors, the same hygiene you apply to any HTTP client, but the per-window 429 problem and its reset-timestamp choreography are simply gone. For the migration path off subscription and marketplace providers, see the GetXAPI vs twitterapi.io comparison and the migrating from twitterapi.io guide, and for an end-to-end read pipeline the Twitter sentiment analysis tutorial shows the pattern in context.
If you want the conceptual grounding on why platforms throttle at all, this explainer covers the system-design reasoning behind rate limiting and throttling:
https://www.youtube.com/watch?v=9CIjoWPwAhU
Summary
Twitter API rate limits come down to a small set of rules worth keeping in front of you. Reads use a 15-minute rolling window, writes use a 24-hour window, and the window starts on your first request rather than at a clock boundary. Each endpoint has its own budget, split between a shared Bearer (app) bucket and per-user OAuth buckets, which is why the same call can show two different limits. A 429 is a recoverable timing error: read x-rate-limit-reset, wait, and retry with backoff and jitter so you never start a thundering herd. Pay-per-use changed billing, not the windows, and even added a monthly read ceiling, so the limits are still there.
The practical decision is about your workload. If you write more than you read, the official windows rarely bite and the standard retry code is enough. If you read heavily, real-time, or in unpredictable bursts, managing the 15-minute window becomes a constant tax, and a per-call API with no window caps removes the problem instead of mitigating it. Start with the pricing page to see per-call rates, model your read and write volume with the cost calculator, and check where the per-call path beats the windowed one on the rate limited vs no-cap comparison.
Frequently Asked Questions
The X API enforces per-endpoint rate limits in two window types. Most read endpoints use a 15-minute rolling window, and post creation uses a 24-hour rolling window. Limits vary by endpoint and auth method. Tweet search allows roughly 450 requests per 15 minutes on Bearer (app) token auth and about 300 on user OAuth, while tweet lookup allows several thousand per window. When you exceed the limit for an endpoint, the API returns a 429 Too Many Requests error and you must wait until the window resets. The exact ceilings are published on docs.x.com and change with the tier model, so always read the x-rate-limit-limit header for the live number.
Most read endpoints use a 15-minute rolling window. Post creation and other write endpoints use a 24-hour rolling window. Rolling means the window is counted from your first request inside it, not from a fixed clock time like the top of the hour. After the window expires the limit resets automatically with no action needed from you. The free tier is the exception: because it has no read access, there is no 15-minute read window to track, only a monthly post-creation cap.
Read the x-rate-limit-reset header, which is a Unix timestamp, and convert it to a wait duration with reset_time minus time.time(). Sleep that many seconds before retrying. If a Retry-After header is present instead, use that value directly since it is already expressed in seconds. Cap your retries at three to five attempts, use exponential backoff with random jitter to avoid a thundering herd when multiple workers hit the limit at once, and never retry a 400, 401, or 403 because those are permanent errors that waiting will not fix. The full retry decorator pattern is in the backoff section of this guide.
The free tier is write only with no read access, so the only active limit is post creation: 1,500 posts per calendar month, enforced as a monthly cap rather than a per-15-minute window. Search, timeline reads, user lookups, and every other read endpoint return 403 Forbidden on the free tier regardless of rate-limit state, because the tier never grants read access at any volume. That means there is no per-minute read budget to manage on the free tier. The only number that matters is the 1,500 monthly post ceiling, plus a short per-window write cap to stop bursts.
A 429 Too Many Requests response means you have exhausted the rate limit for that endpoint in the current window. The response carries three headers that tell you exactly what happened: x-rate-limit-remaining (which is 0 at this point), x-rate-limit-reset (a Unix timestamp marking when the window resets), and x-rate-limit-limit (the cap for that endpoint). You must wait until the time in x-rate-limit-reset before a retry will succeed. A 429 is recoverable by waiting, unlike a 403 which means your tier has no access to the resource at all.
It depends entirely on the endpoint. Tweet search on a Bearer token allows about 450 requests per 15 minutes, which is a theoretical ceiling near 43,200 calls per 24 hours if you ran flat out. Tweet lookup allows several thousand per 15-minute window, and post creation allows on the order of 10,000 writes per 24 hours on app auth. On the free tier the only active endpoint is tweet creation, capped at 1,500 posts per month total. Pay-per-use accounts also face a calendar-month read ceiling before Enterprise pricing is required, which is a separate limit from the per-window caps.
Yes. Moving to the pay-per-use billing model does not remove per-endpoint rate limit windows. The 15-minute and 24-hour windows still apply on the official X API whether you are billed per resource consumed or held a legacy subscription. Pay-per-use changed how you are charged, not how fast you can send requests. On top of the per-window caps, pay-per-use adds a calendar-month read ceiling, so you can hit a limit two different ways: a 429 when a window is exhausted, and a hard stop when the monthly read cap is reached.
On the official X API, no. Per-endpoint windows are enforced at the platform level and apply to every account. You can soften the impact with request queueing, response caching to avoid redundant calls, parallelizing across multiple user OAuth tokens so each gets its own bucket, and reading x-rate-limit-remaining to slow down before you hit zero. Third-party read APIs take a different approach: providers like GetXAPI bill per call with no platform-level window caps, so there is no 429 from window exhaustion to manage. You still add retries for transient network errors, but the per-window rate-limit problem goes away for read-heavy workloads.
Check out similar blogs
More guides on the Twitter/X API, scraping, and pricing.

The Best Twitter (X) API Alternatives in 2026, Compared
The best Twitter / X API alternatives in 2026, ranked and compared: managed pay-per-call APIs, web-data marketplaces, and open-source libraries, with real per-1,000-tweet costs.

How to Like a Tweet via API in 2026 (No Dev Account)
Like (favorite) tweets programmatically via API in 2026 without an X developer account. The auth_token model, working curl, Python, and Node code, and per-call cost.

Post Tweets via API With Authentication in 2026 (No Developer Account)
Post tweets, threads, and media through an API without an X developer account. The auth_token model, working Python and Node code, rate-limit safety, and per-call costs.

How to Detect X (Twitter) Bots: A Practical, Data-Backed Method
A practitioner method for Twitter bot detection: the real signals (views-to-likes ratio, account age, posting cadence, follower pattern, amplification), runnable API code to pull each one, and a scoring rubric you own.

Is the Twitter API Free in 2026? What the Free Tier Actually Gives You
The X API free tier is write only: 1,500 posts a month, zero read access. Here is the full 2026 cost ladder and where pay-per-call APIs fit for read-heavy work.

Twitter API Tutorial 2026: The Complete Developer Guide
The 2026 Twitter API tutorial built after the pricing collapse. Auth, endpoints, code, rate limits, real costs, and the alternative when official gets too expensive.

RapidAPI Twitter Alternative: Direct API vs Marketplace
Picking a RapidAPI Twitter alternative? Compare marketplace listings against the official X API and GetXAPI on price, uptime, billing, and migration.

Twitter API 403 Forbidden and 401 Unauthorized: Every Cause and Fix
Why the X API returns 403 Forbidden or 401 Unauthorized, how to tell the two apart, and a fix for each cause. Covers tier gating, app permissions, OAuth, and X error codes.