X API Pricing Change (April 2026): $0.20 Per-Link Tweets Explained
X changed its API pricing on April 20, 2026: posts with a URL jumped to $0.20, owned reads dropped to $0.001, and follow/like/quote-post moved to Enterprise-only. Here is what each change costs and what to do next.
: $0.20 Per-Link Tweets Explained")
On April 20, 2026, X changed how its API is priced, and the change rippled through every project that touches the platform programmatically. The headline number doing the rounds is a 1,900 percent increase on a single action: posting a tweet that contains a link. Plenty of developers found out the hard way, watching prepaid credit balances drain in weeks instead of years.
TL;DR: On April 20, 2026 the X API moved to a sharper pay-per-use model. Owned-account reads dropped to $0.001, plain writes went from $0.010 to $0.015, and posts containing a URL jumped from $0.010 to $0.20 (a 1,900 percent increase). Following, liking, and quote-posting left self-serve and became Enterprise-only. If you auto-publish links, you are paying 13x more per post. If you only read public tweets, a per-call read API at $0.05 per 1,000 reads is the cheaper path. This guide breaks down each change, who got hit, and the concrete options.
This post is the plain-language explainer for that change. We will walk through exactly what moved, what each action costs now, who the change hits hardest, what developers are actually doing about it, and the practical alternatives if your build relied on the old pricing. Where the numbers get into long-term cost modeling, we point you to our dedicated cost math guide rather than re-deriving the whole spreadsheet here.

That single number is why this change spread so fast. A 1,900 percent jump on one action is the kind of thing that turns a quiet monthly bill into an emergency. Below, we break down what actually changed, because the link-tweet price is only one of three moving parts.
What Actually Changed on April 20, 2026
The April 2026 update was not a single price bump. It was a restructuring of the pay-per-use model into sharper bands, plus a quiet move of several common actions out of self-serve entirely. According to the official X Developers pricing changelog, three things happened at once.
First, owned-account reads dropped to $0.001 per read. If you are reading data from an account you control, that is now very cheap. Second, standard writes (creating a plain text or media post with no URL) moved from $0.010 to $0.015 per request, a modest bump. Third, and this is the one everyone is talking about, posts containing a URL jumped from $0.010 to $0.20 per request. The shift to a finer-grained usage-based model was framed by the platform as broadening developer access, a framing covered in Social Media Today's report on the usage-based access charges, though the per-action numbers are what the affected developers actually felt.
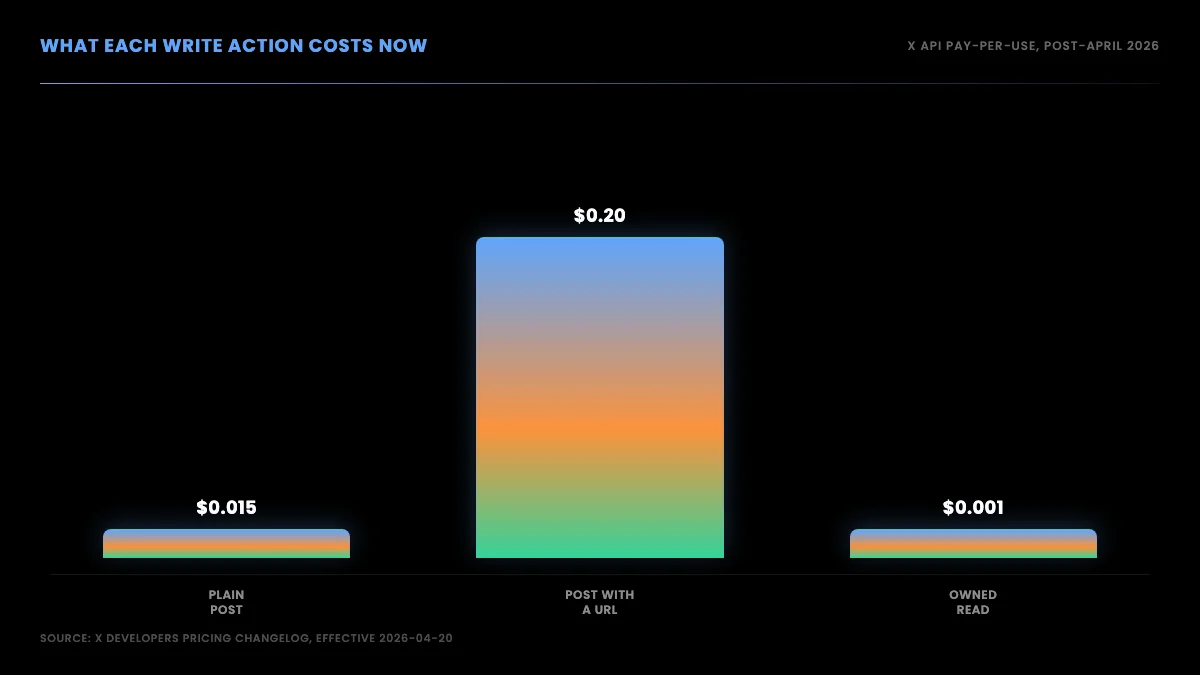
The gap in that chart is the whole story. A plain post and a link post used to cost the same. Now a link post costs more than 13 times a plain post. For any account that auto-publishes content with a URL in the body, the per-post cost did not nudge up, it changed category.
On top of the price restructuring, X moved three actions off pay-per-use and into Enterprise-only access on the same date: following accounts, liking posts, and quote-posting. If your build depended on any of those through the self-serve API, you cannot simply pay more per call anymore. You need an Enterprise contract or a different design.

That access shift is easy to miss under the noise about the link price, but it is arguably the bigger architectural problem. A price you can budget for. An action that is no longer available on your tier forces a redesign.
The Before-and-After Rate Card
It helps to see the old and new prices side by side, because the restructuring is easy to misread when you only hear the $0.20 headline. The table below covers the actions that most self-serve projects actually use.
| Action | Before April 20 | After April 20 | Change |
|---|---|---|---|
| Plain post (text or media) | $0.010 | $0.015 | +50% |
| Post containing a URL | $0.010 | $0.20 | +1,900% |
| Owned-account read | varied | $0.001 | sharply lower |
| Follow an account | pay-per-use | Enterprise-only | removed from self-serve |
| Like a post | pay-per-use | Enterprise-only | removed from self-serve |
| Quote-post | pay-per-use | Enterprise-only | removed from self-serve |
Three patterns jump out. The owned-read drop to $0.001 is a genuine win if you are pulling data from accounts you control. The plain-post bump to $0.015 is small enough that most posting bots will not notice it. And the link-post price is the outlier by an order of magnitude, which is exactly why it dominated the conversation. The Enterprise-only shift, listed in the bottom three rows, is the change that has no cheaper workaround at all.
One nuance worth stating plainly: the link price is evaluated on the post body. A post that contains https:// anywhere in its text is billed at $0.20, regardless of whether the link is the point of the post or an afterthought. There is no partial rate for a short link or a link to your own domain. The classifier is binary, so a single trailing URL flips the whole post into the expensive band.
Doing the Cost Math at Real Volumes
Abstract percentages do not communicate the impact the way a monthly bill does, so let us run the numbers at a few realistic posting volumes. Assume an account that posts content with a link in the body, which describes most newsletter relays, blog syndicators, and alert accounts.
At 10 posts per day, that is roughly 300 link-posts a month. At the old rate of $0.010 per post, that cost $3.00 a month, the kind of number nobody budgets for because it is rounding error. At the new $0.20 rate, the same 300 posts cost $60.00 a month. The workload did not change. The output did not change. The bill went up 20x.
Scale that to a busier account at 50 link-posts per day, around 1,500 a month, and the old cost was $15.00 while the new cost is $300.00. At 100 link-posts per day, a high-output news or alert bot, you move from $30.00 to $600.00 a month. None of these are enterprise volumes. They are the everyday cadence of a useful automated account, and the change pushed each of them into a price bracket that a hobby project or a non-commercial public-service account cannot absorb.
Now compare that to a read-only workload at the same scale. Reading 1,500 tweets a month for monitoring costs about $0.075 on a per-call read API at $0.05 per 1,000 reads. The asymmetry is the whole point: writes, especially link-writes, are where the new pricing concentrates the cost, and reads are cheap by comparison. If your project conflated the two onto one expensive tier, splitting them is the single highest-leverage change you can make. For the full workload-by-workload trajectory across a 12-month horizon, the cost math guide carries the detailed spreadsheet.
Who Got Hit Hardest
The change does not land evenly. A read-heavy analytics pipeline barely notices it, or even benefits from the cheaper owned reads. An automated publishing account that always posts a link feels it immediately. Here is a quick way to figure out where you sit.

The accounts hit hardest are the ones that post links at volume: newsletter auto-posters, blog syndication bots, RSS-to-X relays, affiliate posters, and public-service alert accounts. Every one of their posts carries a URL, so every post moved into the $0.20 band overnight.
The clearest public example came from a small cybersecurity awareness account that loaded $500 in API credits in April expecting it to last the year. It lasted 34 days. They posted plain-English security warnings with links to sources, which meant every post hit the new link price.
https://x.com/cybernewslive/status/2062165741973991758
That thread is worth reading in full because it captures the pattern: a non-commercial project, no scraping, no bots farming data, just posting links to useful information, suddenly facing a bill it could not sustain. The frustration in the developer community was immediate and loud.
https://x.com/JasonBotterill/status/2058887073990693065
The complaint that the API is too expensive for ordinary use predates April, but the change sharpened it. Even people who would happily pay a fair rate found the new link pricing hard to justify for small projects.
https://x.com/mreiffy/status/2059878453638209629
Some accounts simply could not keep up with their own posting volume. A widely-followed reporting bot that mirrors a high-output public figure did the math and warned it might have to shut down, because the cost scaled directly with how often the source posted.
https://x.com/WHPressPool/status/2061893193785045116
What ties these examples together is that none of them are abusive use. There is no data harvesting, no spam farm, no attempt to game the platform. They are utility accounts and reporting tools that posted links to useful information, which is precisely the behavior the new link price makes expensive. The result is that the projects most likely to disappear are the low-margin, high-value ones: the volunteer-run alert feeds, the niche research bots, the civic-information accounts. Commercial operations with revenue can usually absorb a higher per-post cost or negotiate an Enterprise rate. The long tail of free, useful automation cannot, and that is the part of the ecosystem visibly thinning out.
The pattern shows up on Reddit too, where developers and project maintainers have been comparing notes on what broke and what they switched to.
X / Twitter data is too expensive, so I fixed it from r/webdev
When a developer titles a thread "so I fixed it," the fix is almost always the same shape: stop paying the official write or read premium and route the workload somewhere cheaper. That instinct, build or buy around the price, is the dominant response in the developer threads. The same caution shows up among people weighing whether to pay at all.
Be Careful Before Paying for Twitter / X API from r/Twitter
These are not edge cases. They are the everyday utility bots and integrations that quietly ran for years and suddenly stopped making financial sense.
Start building with GetXAPI
$0.05 per 1,000 tweets. $0.10 free credits. No credit card required.
What Developers Are Doing About It
Across public posts and threads from May and June 2026, the responses cluster into a handful of patterns. None of them are surprising once you see the cost structure, but it helps to name them.
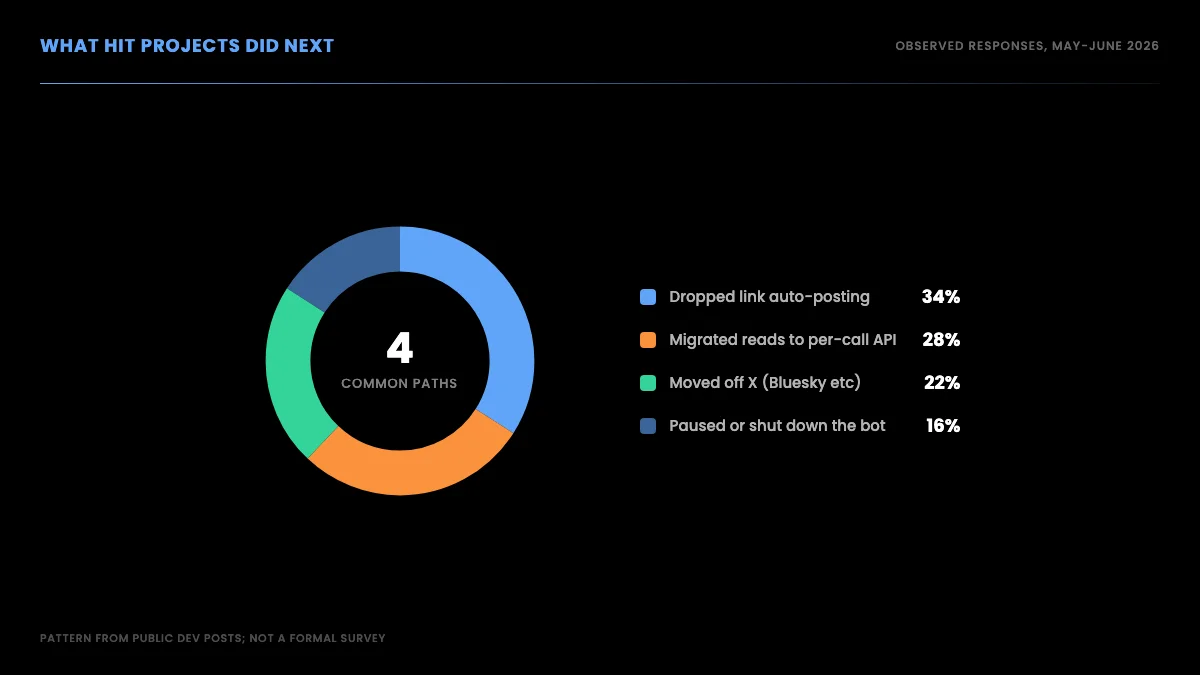
The single most common move is the simplest: stop putting links in posts, or move the link to a reply where it is billed at the standard write rate instead of the link rate. The second most common is to separate read workloads from write workloads and route the reads through a cheaper per-call API. If you are weighing the read options, our breakdown of the best ways to scrape and read tweets compares the approaches on cost and reliability. The third is migration off the platform entirely, which is why a wave of academic paper bots and alert accounts announced moves to Bluesky in early June. The fourth, sadly, is shutting the project down.
If your project is read-heavy, the good news is that reading public tweets never required the expensive write path in the first place, and there are now several ways to do it for a fraction of the official cost.
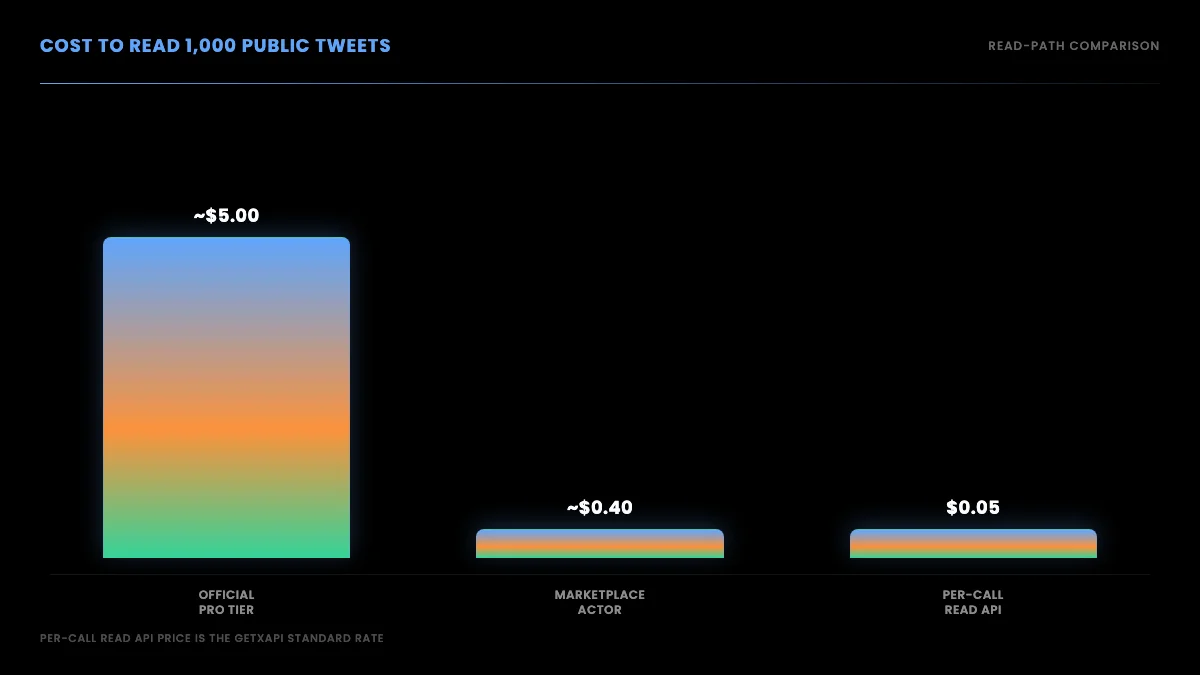
The read-path gap is wide. The official Pro tier works out to roughly $5.00 per 1,000 reads, a marketplace scraper actor lands around $0.40 per 1,000 once you factor proxy overhead, and a per-call read API like GetXAPI is $0.05 per 1,000 reads with no monthly minimum. For pure read workloads, the per-call route is both the cheapest and the least operationally fragile.
If You Post Links: How to Cut the $0.20 Cost
If posting is core to your project and you cannot just stop, there are still ways to bring the bill down without going Enterprise. The key insight is that the $0.20 band applies specifically to the body of a post containing a URL. A plain post is still $0.015.
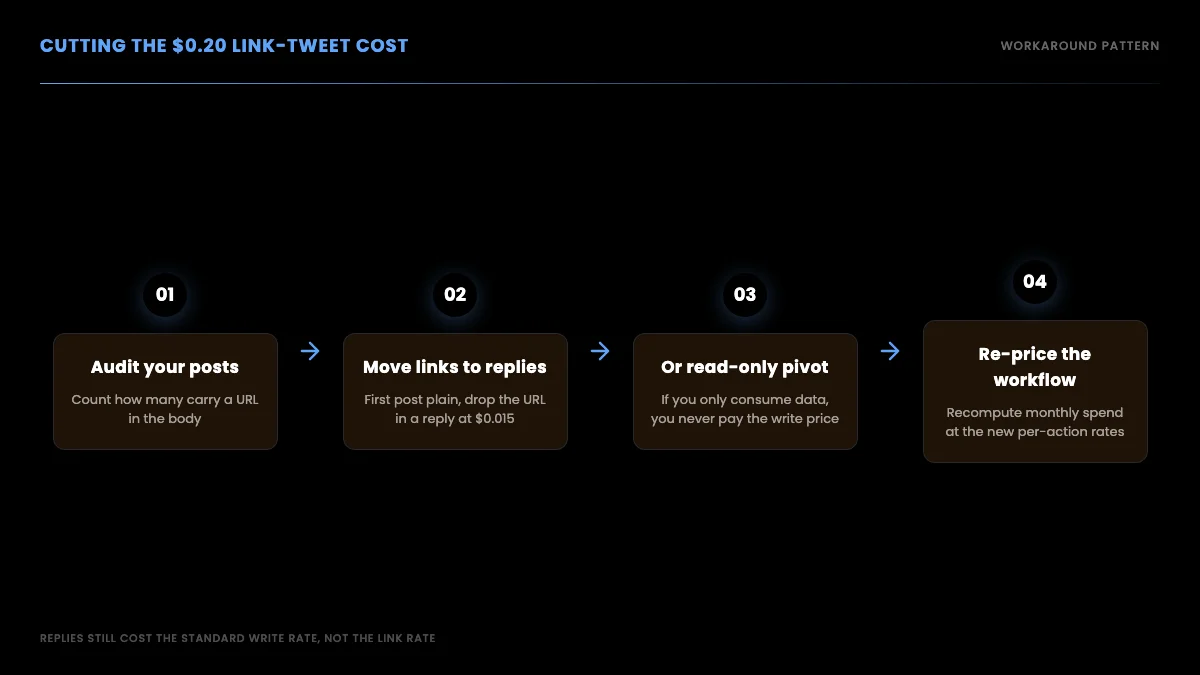
The most common workaround is to post the main content as a plain text post, then drop the URL in a reply. Replies are billed at the standard write rate, not the link rate, so a post-plus-reply pattern costs roughly $0.015 plus $0.015 instead of a flat $0.20. That is a meaningful saving at volume, though it does change how the post renders in a follower's timeline, so test whether it fits your use case.
Before you re-architect anything, audit how many of your posts actually carry a URL. Many accounts assume they are link-heavy and discover that only a minority of posts include one. Then re-price the whole workflow at the new per-action rates so you are planning against real numbers, not the old mental model. For a full 12-month spend trajectory at different volumes, our cost math guide has the workload-by-workload breakdown.
The real bills coming in tell you why this matters. A budget that was supposed to cover a year of posting was burning out in a month for link-heavy accounts.

That 34-day figure is the part that makes the change feel less like a price adjustment and more like a wall. When the cost scales directly with how useful your account is (more posts, more links, more cost), small projects get squeezed first.
If You Read Public Data: The Per-Call Alternative
A large share of projects that touch the X API never needed to post at all. They read public tweets for sentiment analysis, monitoring, research, lead enrichment, or dashboards. For those workloads, the April change is mostly an opportunity to re-examine whether you were overpaying on the read side too.

A per-call read API removes the two things that make the official path painful for read workloads: the OAuth setup and the monthly minimum. You authenticate with a single bearer token, call a REST endpoint, and pay only for the requests you make. Here is a minimal read call against GetXAPI that fetches a public user profile. This is a live, runnable example.
import requests
API_KEY = "YOUR_API_KEY"
BASE = "https://api.getxapi.com"
resp = requests.get(
f"{BASE}/twitter/user/info",
headers={"Authorization": f"Bearer {API_KEY}"},
params={"userName": "elonmusk"},
timeout=30,
)
resp.raise_for_status()
data = resp.json()["data"]
print(f"{data['name']} (@{data['userName']})")
print(f"Followers: {data['followers']:,}")
print(f"Tweets: {data['statusesCount']:,}")
That returns a structured JSON object with the public profile fields: name, handle, follower count, tweet count, bio, and account creation date. No developer-account approval, no rate-limit window engineering, and no monthly commitment.
If you would rather test from the shell before writing any code, the same call works as a one-line curl. This is the fastest way to confirm your key works and see the response shape.
curl -s "https://api.getxapi.com/twitter/user/info?userName=getxapi" \
-H "Authorization: Bearer YOUR_API_KEY"
A good habit when moving off the official API is to keep the key in an environment variable rather than hard-coding it, so the same script runs in local dev and production without edits. The read call then pulls the key from the environment.
import os
import requests
API_KEY = os.environ.get("GETXAPI_KEY", "YOUR_API_KEY")
BASE = "https://api.getxapi.com"
resp = requests.get(
f"{BASE}/twitter/user/info",
headers={"Authorization": f"Bearer {API_KEY}"},
params={"userName": "getxapi"},
timeout=30,
)
print("status:", resp.status_code)
print("handle:", resp.json()["data"]["userName"])
Searching public tweets works the same way. The advanced search endpoint takes a query string and a query type, and returns matching tweets with their engagement counts. The query supports the standard search operators, so you can filter by keyword, engagement threshold, or date. Here is a live search call that pulls recent high-engagement tweets discussing the API change itself.
import requests
API_KEY = "YOUR_API_KEY"
BASE = "https://api.getxapi.com"
resp = requests.get(
f"{BASE}/twitter/tweet/advanced_search",
headers={"Authorization": f"Bearer {API_KEY}"},
params={"q": "x api pricing min_faves:20", "queryType": "Top"},
timeout=30,
)
resp.raise_for_status()
payload = resp.json()
tweets = payload["tweets"]
print(f"Found {payload['tweet_count']} tweets")
for t in tweets[:5]:
print(f"- {t['likeCount']} likes | {t['text'][:80]}")
The response includes tweet_count, a next_cursor for pagination, and a tweets array where each item carries id, text, likeCount, retweetCount, viewCount, createdAt, and more. You pay per call at $0.05 per 1,000 reads, billed separately from any write action, so the $0.20 link price never enters the picture for a read-only build.
To pull more than one page of results, follow the next_cursor until the response stops returning one. This is the cursor pagination pattern, and it replaces the window-based pagination of the official API. The loop below caps itself at three pages to keep the example cheap and fast.
import requests
API_KEY = "YOUR_API_KEY"
BASE = "https://api.getxapi.com"
headers = {"Authorization": f"Bearer {API_KEY}"}
cursor = None
collected = []
for _ in range(3):
params = {"q": "x api pricing", "queryType": "Latest"}
if cursor:
params["cursor"] = cursor
r = requests.get(f"{BASE}/twitter/tweet/advanced_search",
headers=headers, params=params, timeout=30)
r.raise_for_status()
page = r.json()
collected.extend(page.get("tweets", []))
cursor = page.get("next_cursor")
if not page.get("has_more") or not cursor:
break
print(f"Collected {len(collected)} tweets across pages")
Wrapping the call in basic error handling keeps a read job resilient against the occasional timeout or transient error, the same defensive pattern you would use against any HTTP API. A 401 means the key is wrong, a 429 means you are calling too fast, and a 5xx is worth a short retry.
import requests
API_KEY = "YOUR_API_KEY"
BASE = "https://api.getxapi.com"
try:
r = requests.get(
f"{BASE}/twitter/user/info",
headers={"Authorization": f"Bearer {API_KEY}"},
params={"userName": "getxapi"},
timeout=30,
)
r.raise_for_status()
print("ok:", r.json()["data"]["userName"])
except requests.exceptions.HTTPError as e:
print("HTTP error:", e.response.status_code)
except requests.exceptions.RequestException as e:
print("request failed:", type(e).__name__)
If you prefer to see the workflow end to end before writing code, this walkthrough covers getting set up to pull X data without wrestling the official developer console.
https://www.youtube.com/watch?v=aZz9D0FdevA
Beyond the price, the operational story matters for read workloads. The official API enforces rate-limit windows that you have to engineer around with token buckets and backoff logic, and a single noisy job can exhaust a window and stall the rest of your pipeline. A per-call model meters by request rather than by window, so you size capacity by budget instead of by a fixed quota you cannot exceed. For teams that spent real engineering hours building rate-limit accounting against the official tiers, removing that complexity is often worth as much as the price difference. The search operators reference covers how to write precise queries that pull only the tweets you need, which keeps the read count, and therefore the bill, low.
The takeaway for read workloads is straightforward: the write-side price change does not have to touch you. Point your reads at a per-call endpoint, keep your bearer token in an environment variable, and your cost tracks usage instead of a tier you have to grow into.
How the Three Paths Compare
Once you know which actions your project needs, the decision narrows quickly. The three realistic paths after April 2026 are: stay on the official X API and absorb the new prices, move read workloads to a per-call API, or sign an Enterprise contract for the actions that left self-serve.

If you must post tweets programmatically, the official API is still the only first-party path, and you manage the link cost with the reply workaround. If you need to follow, like, or quote-post at scale, Enterprise is now the only option, and the monthly minimum starts in the tens of thousands. If your needs are read-only, a per-call read API covers them with no minimum and no OAuth, which is why so many read-heavy projects made that switch first.
For a deeper side-by-side on endpoints, auth, and rate limits between the official API and a per-call alternative, see our Twitter API v2 vs GetXAPI comparison and the search operators reference for building precise queries.
The cheapest Twitter API. Try it free.
$0.05 per 1,000 tweets. $0.10 free credits. No credit card required.
A Migration Checklist for Read Workloads
If you decide to move read traffic off the official API, the migration is usually a small amount of work because the data shapes are similar. Here is the order that keeps it low-risk.
Start by inventorying every place your code reads X data. In most projects this is a handful of functions: a search call, a user-lookup call, maybe a timeline pull. Write down the fields you actually consume downstream, because you almost never use every field the official API returns, and matching the subset you need is faster than matching everything.
Next, swap the auth. The official API uses OAuth or app-only bearer tokens with their own scoping rules. A per-call read API like GetXAPI uses a single bearer token in an Authorization header, so you replace the OAuth client with one environment variable. Keep the key out of source control and read it from the environment, exactly as in the code samples above.
Then map the endpoints. A user lookup maps to the user-info endpoint, a keyword search maps to the advanced-search endpoint with a q parameter, and pagination uses a cursor returned in the response rather than the official token-based pagination. The response fields (text, author handle, like and retweet and view counts, timestamps) carry the same meaning, so your downstream parsing changes very little. If you are building in Python, the full Python Twitter API tutorial walks through the request patterns end to end.
Finally, run both paths in parallel for a day. Point a copy of your read job at the new endpoint, compare the output against the official path, and confirm the fields line up before you cut over. Once the parallel run matches, flip the live job and decommission the old credentials. Because reads are billed per call with no monthly minimum, there is no sunk subscription to strand and no commitment to unwind.
For projects that need to post, the migration is different and more limited. Posting is still a first-party action, so the realistic move is the reply-link workaround plus a hard audit of how many posts truly need a URL. If follow, like, or quote-post were load-bearing in your design, the only first-party path now is Enterprise, and the honest answer is to re-scope the feature rather than pretend a cheap workaround exists.
The Questions Developers Kept Asking
In the weeks after the change, the same handful of questions came up again and again in threads and support channels. They are worth answering directly because the confusion around them caused a lot of the panic.
The first was whether the new pricing was retroactive. It was not. The change applied to requests made on or after April 20, 2026. Credits you had already spent were not repriced. The shock for most people came not from a retroactive charge but from how fast a freshly-loaded balance drained at the new rates, which felt retroactive even though it was not.
The second was whether reads went up too. For most read paths, no. The owned-account read price went down to $0.001. General reads are billed under their own structure, and the action that changed dramatically was the link-write, not reads. This matters because a lot of developers assumed the worst and started ripping out read pipelines that were never affected. If you only read public data, the calmest move was to do nothing on the official side and simply check whether a cheaper per-call read API made sense regardless.
The third was what exactly counts as a URL for the $0.20 band. The practical answer is that any http:// or https:// string in the post body triggers it. Shortened links count. Links to your own domain count. A link in an attached media card behaves differently from a link in the text, so if you can express the link as a card or move it to a reply, you avoid the body-link price. Test your specific posting pattern, because the rendering and billing interact in ways that are easy to assume wrong.
The fourth was whether there is a grace path for non-commercial or public-interest accounts. As of the change, there is no special self-serve tier for non-commercial use. The free Basic tier remains write-limited and is not a workable home for an active link-posting account. Several public-interest projects concluded that the platform no longer fit their budget and moved their primary feed elsewhere, which is why the early-June migration announcements clustered the way they did.
What This Change Signals
Zoom out and the April 2026 update fits a clear direction. X is steering high-frequency automated posting toward Enterprise and pricing casual self-serve link-posting out of reach, while making owned-account reads cheap to encourage first-party use. That is a coherent strategy from the platform's side, even if it is painful for the long tail of small bots and integrations that ran on the old flat rate.
For developers, the practical lesson is to decouple read and write workloads and price each against its real per-action cost. A read pipeline and a posting bot are different products with different economics, and bundling them onto one expensive tier is what made the change hurt. Splitting them, and routing reads to a per-call API, is what most of the affected projects ended up doing.
There is also a portfolio lesson here about platform risk. Any project that depends on a single platform's pricing is exposed to exactly this kind of overnight repricing, with no notice and no grace period. The accounts that weathered the change best were the ones that had already abstracted their data layer behind their own interface, so swapping the provider underneath was a configuration change rather than a rewrite. If your code calls a platform API directly throughout your codebase, a pricing shock forces a scramble. If it calls your own thin wrapper that happens to talk to a provider, you change one module. The April change is a good prompt to introduce that seam if you have not already, because the next repricing, on this platform or another, will not announce itself any earlier than this one did.
It is also worth being clear-eyed that this is not unique to X. Every major platform that opened an API in the last decade has, at some point, tightened or repriced it once the dependent ecosystem was large enough to monetize. The most-cited recent precedent is Reddit's 2023 API repricing, reported widely at the time, which shut down a generation of third-party clients almost overnight. The specific numbers differ, but the shape repeats: cheap or free access to build the ecosystem, then a price that captures value once developers are committed. Planning for that cycle, rather than being surprised by it, is the durable takeaway. Keep your data access loosely coupled, know which workloads are read versus write, and keep a tested fallback provider in your back pocket so a pricing change is an inconvenience instead of an outage.
The Verdict
The April 20, 2026 X API change is real, it is significant, and it lands hardest on projects that auto-post links. The three concrete moves that came out of it are: cut or relocate links to dodge the $0.20 band, separate reads from writes, and route read workloads to a per-call API at $0.05 per 1,000 reads instead of the official $5.00. The Enterprise-only shift for follow, like, and quote-post is the part to watch if your build depended on those actions, because there is no cheaper workaround for them.
If your project is read-heavy, you can stop paying for a write path you never used. A single bearer token, a REST call, and per-request billing cover most read workloads without a monthly minimum or a developer-account queue. You can sign up and run your first read in a few minutes, or check the current rates on the pricing page before you migrate.
Frequently Asked Questions
Three things changed. Owned-account reads dropped to $0.001 per read. Standard writes (a plain text or media post) moved from $0.010 to $0.015 per request. Posts containing a URL jumped from $0.010 to $0.20 per request, a 1,900 percent increase. On the same date, following accounts, liking posts, and quote-posting were removed from pay-per-use and made Enterprise-only.
The pay-per-use model has no standing free monthly read allowance the way older tiers did. You purchase credits and draw them down per request. The free Basic tier that remains is write-limited (a small monthly post cap, no meaningful read access), so for reading public tweet data at any volume you are paying per request or per credit.
Public posts from affected developers cluster into four responses: dropping link auto-posting to avoid the $0.20 band, moving read workloads to a cheaper per-call read API, migrating off X entirely (several paper and alert bots moved to Bluesky), and pausing or shutting down bots that could no longer cover costs.
No. The $0.20 price is a write-side charge: it applies when you post a tweet that contains a URL. Reading tweets is billed separately. If your project only consumes public tweet data and never posts, the link-tweet change does not affect you at all, and the owned-read drop to $0.001 may even help.
X moved link-bearing posts into their own price band at $0.20 each, separate from plain posts at $0.015. If your workflow auto-publishes newsletter links, blog URLs, YouTube links, or affiliate URLs, every one of those posts is now more than 13 times the price of a plain-text post. The change lands hardest on automated publishing accounts that always include a URL.
Not on pay-per-use. As of April 20, 2026, following accounts, liking posts, and quote-posting were moved to Enterprise-only access. If your build relied on any of those actions through the self-serve API, you now need an Enterprise contract (which starts in the tens of thousands per month) or you redesign around them.
It depends on the path. The official Pro tier works out to roughly $5.00 per 1,000 reads. A marketplace scraper actor runs around $0.40 per 1,000 depending on proxy overhead. A per-call read API like GetXAPI is $0.05 per 1,000 reads with no monthly minimum. For read-only workloads the per-call route is usually the cheapest and the simplest to operate.
Point your read calls at a per-call API that returns the same public fields (tweet text, author, engagement counts, timestamps). With GetXAPI you authenticate with a single bearer token, call a REST endpoint for search or user data, and pay per request at $0.05 per 1,000 reads. There is no OAuth flow, no developer-account approval queue, and no monthly minimum. See the [pricing](/pricing) page for the current rate card.
Check out similar blogs
More guides on the Twitter/X API, scraping, and pricing.

How to Get Notified When Someone Tweets on X (2026 Guide)
Get notified when someone tweets, in real time. Webhooks push every new post to your server, Slack, or a Discord bot. Keyword alerts, code, scale math, and costs.

Is the Twitter API Free in 2026? What the Free Tier Actually Gives You
The X API free tier is write only: 1,500 posts a month, zero read access. Here is the full 2026 cost ladder and where pay-per-call APIs fit for read-heavy work.

Twitter API 403 Forbidden and 401 Unauthorized: Every Cause and Fix
Why the X API returns 403 Forbidden or 401 Unauthorized, how to tell the two apart, and a fix for each cause. Covers tier gating, app permissions, OAuth, and X error codes.

The Best Twitter (X) API Alternatives in 2026, Compared
The best Twitter / X API alternatives in 2026, ranked and compared: managed pay-per-call APIs, web-data marketplaces, and open-source libraries, with real per-1,000-tweet costs.

How to Like a Tweet via API in 2026 (No Dev Account)
Like (favorite) tweets programmatically via API in 2026 without an X developer account. The auth_token model, working curl, Python, and Node code, and per-call cost.

Post Tweets via API With Authentication in 2026 (No Developer Account)
Post tweets, threads, and media through an API without an X developer account. The auth_token model, working Python and Node code, rate-limit safety, and per-call costs.

Twitter API Performance Benchmark 2026: Latency, Reliability, Throughput
A real Twitter/X API performance benchmark: measured per-endpoint latency (p50/p95), 100% reliability across 44 calls, and throughput math, with how it compares to the official API.

How to Detect X (Twitter) Bots: A Practical, Data-Backed Method
A practitioner method for Twitter bot detection: the real signals (views-to-likes ratio, account age, posting cadence, follower pattern, amplification), runnable API code to pull each one, and a scoring rubric you own.